

目次
RAGとは
検索拡張生成 RAGは、 大規模な言語モデルの出力を最適化するプロセスです。そのため、応答を生成する前に、トレーニングデータソース以外の信 頼できる知識ベースを参照します。生成AIの回答精度を高められるとして注目を集めている技術です。特にビジネスで生成AIを活用する際に重宝されています。
大規模言語モデル(LLM)は、膨大なデータをもとにトレーニングされ、数十億のパラメータを用いて質問への回答、翻訳、文章の補完などのタスクに独自の出力を生成します。RAGは、モデルを再トレーニングせずに、LLMの優れた機能を特定の分野や組織内のナレッジベースに拡張します。これは、LLMの出力の精度や関連性を向上させる費用対効果の高い方法であり、多様な場面で正確で有用な情報提供が可能です。
RAGを使うメリット
コスト効率の高い実装
チャットボットの開発は、通常、基盤モデルを利用して始めます。基盤モデル(FM)は、広範なデータやラベル付けされていないデータで学習された、API経由でアクセスできる汎用的なLLMモデルです。FMを組織や特定の分野向けに再トレーニングするには、高い計算コストと経済的負担が発生します。一方で、RAGはLLMに新しいデータを導入する際の、よりコスト効率の良い方法です。これにより、生成AI技術はより多くの人に利用しやすくなり、アクセス性が向上します。
情報を最新化
検索機能を活用することで、常に最新の情報にアクセスできるため、生成される内容も最新の情報を反映しています。これにより、常に最新の知識と技術トレンドを踏まえた設計・開発が可能となります。例えば、新しいフレームワークやライブラリの使用例を自動生成されたドキュメントに取り入れられます。
AIの回答内容をコントロールできる
RAGを使用することで、開発者はLLMがアクセスする情報源を選んで制御できるため、特定の分野や用途に応じた正確な応答が得られます。また、データの更新が柔軟にできるため、ビジネス要件の変化や新しい情報にも迅速に対応が可能です。さらに、利用者の権限に応じてアクセス範囲を制限し、機密情報の管理も徹底できます。RAG環境では、LLMが誤った情報源に基づいて回答した場合、開発者が素早く情報源を特定し修正できるため、応答精度の維持も容易です。こうして、RAGは異なる文脈やシナリオに合わせたカスタマイズを可能にし、より信頼性の高い生成AIの導入を支援します。
RAGの仕組み
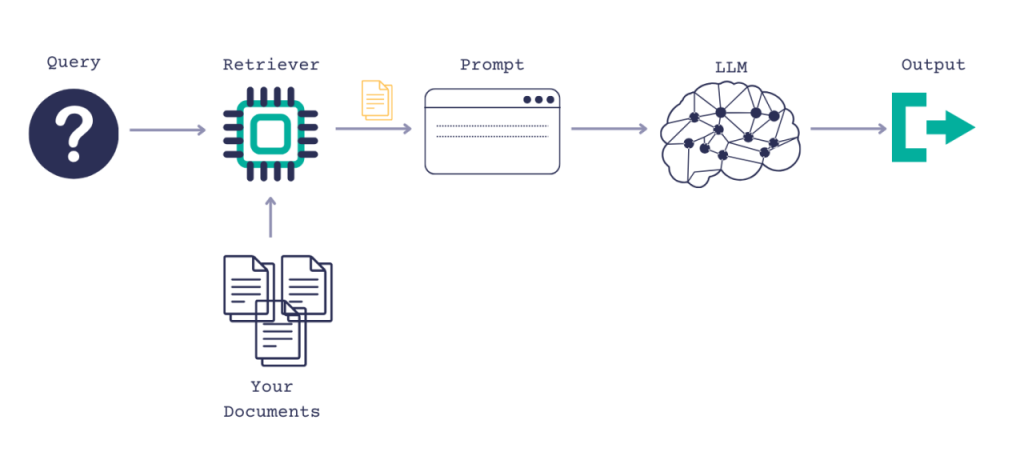
RAGを使用しない場合、LLMはユーザーからの入力を受け取り、トレーニングされたデータや既知の情報に基づいて応答を生成します。これに対し、RAGではまずユーザー入力をもとに、新しいデータソースから情報を引き出す「情報検索」のプロセスが追加されています。ユーザークエリと引き出された関連情報はともにLLMに渡され、LLMはその新しい知識と自身のトレーニングデータを組み合わせて、より適切な応答を生成します。以下のセクションで、このプロセスについて概要を説明します。
外部データの作成
LLMの元のトレーニングデータセットに含まれない新しいデータは「外部データ」と呼ばれます。このデータは、API、データベース、ドキュメントリポジトリなど、さまざまなソースから取得可能です。また、データはファイル形式、データベースのレコード、長文のテキストなど、さまざまな形態で存在する場合があります。埋め込み言語モデルと呼ばれる別のAI技術を使うと、このデータを数値として表現し、ベクトルデータベースに格納できます。この過程を通じて、生成AIモデルが活用できる知識ライブラリが構築されます。
関連するデータの取得
次のステップは関連性検索の実行です。ユーザーのクエリをベクトル形式に変換し、ベクトルデータベースと比較します。たとえば、組織の人事関連の質問に応答できるスマートチャットボットを想像してください。従業員が「明日何かのMTGがある?」と尋ねた際、システムはその従業員のカレンダー情報から取得します。これらの文書は、従業員の質問と密接に関連するため返されます。この関連性は、ベクトルの数学的計算と表現によって導き出され、確立されました。
LLM プロンプトの拡張
次に、RAGモデルは取得した関連データをコンテキストとして追加し、ユーザー入力(またはプロンプト)を強化します。この段階では、プロンプトエンジニアリングの手法を活用して、LLMとの効果的なやり取りを実現します。強化されたプロンプトによって、大規模な言語モデルでもユーザークエリに対する正確な応答が生成されます。
外部データを更新
次に考えられる疑問は、外部データが古くなった場合どうするかという点です。常に最新情報を取得するには、ドキュメントの非同期更新や埋め込み表現の更新が必要です。これには、リアルタイムの自動処理や定期的なバッチ処理が利用できます。この更新管理の課題はデータ分析において一般的であり、データサイエンスのさまざまな手法が役立ちます。
RAGの活用事例
RAGを活用したLLMは非常に柔軟であり、多くの業界で活用できます。
社内データの検索
企業では、社内コンサルタントが業務に関するリサーチやドキュメントの内容確認を担当していましたが、これに多くの時間が費やされ、本来の高価値なコンサルティング業務に集中できない状況でした。そこで、同社はすべての従業員が生成AIを活用できる環境を整備し、調査やドキュメント確認の一部を生成AIに任せることに成功しました。これにより、コンサルタントは顧客対応や社内改革といったコア業務に専念しやすくなりました。
一般に公開されている生成AIは精度に不安があるものの、同社はRAGを活用し、生成AIに必要な情報を組み込むことで、より正確な回答が得られるよう工夫しているようです。
RAGを利用する際の注意点
出力結果は外部情報に依存する
RAGは外部情報を参照して回答を生成するため、組み込まれた文書やデータベースに誤りがある場合、その結果として誤った情報が出力される可能性があります。正確な回答を得るためには、外部情報のファクトチェックや定期的なメンテナンスを行うことが重要です。
機密情報の取り扱いによるトラブルの懸念
RAGでは、プライバシーとセキュリティを確保することが重要です。外部データベースから情報を取得する際、プライバシーやセキュリティに関する問題が発生する可能性があるためです。たとえば、個人情報や機密情報を含むデータベースから情報を取得する場合、不適切な使用や漏洩のリスクが生じる恐れがあります。適切な対策として、データポリシーの策定、データ送受信の暗号化、データベースへのアクセス権限の厳格な管理を行いましょう。
独自性のあるコンテンツを生成することは難しい
RAGの最大の利点は、正確な情報源を参照して、信頼性のあるコンテンツを生成できる点です。しかし、外部情報に存在しないコンテンツを生成するのは難しい一面もあります。RAGは便利な技術ですが、その効果を最大限に引き出すには、コントロールするためのノウハウが必要です。独自性の高いコンテンツを作成する際には、人が担当すべき部分とRAGに任せる部分を明確に分け、共創の意識を持って進めるのが理想です。リソースが不足している場合は、パートナー企業への依頼も有効な手段となります。
まとめ
RAGは、情報検索とテキスト生成を組み合わせた有力な手段であり、業務効率を大幅に向上させる可能性を秘めています。ただし、導入する際にはデータの品質やセキュリティ面への配慮が重要です。
生成AIの活用を検討している方は、ぜひお問い合わせください!
